
Aim of this project was to achieve a full body controllable avatar in the VR environment (Unity). Head and hands are tracked using Head Mounted Display (Quest 2) and two controllers while tracking of the rest of the body parts is achieved using computer vision based 3D pose estimation techniques.
Background
I have completed this project as my Master’s thesis at Aalborg University together with Sofia Lamda. Full body motion tracking enables users to match their physical movements to their virtual avatars. Such process increases the immersion of the virtual reality experience. As part of our project we have compared a selection of tools used for full body poses estimation. We have focused on computer vision full body pose estimation based solutions. Our main goal was to create an accessible solution that does not require sophisticated technology.
Computer vision
Computer vision forms the basis for the automatic identification and analysis of parameters that provide useful information with regard to an object or a scene with the implementation od deep learning models.
In its simplest form, a computer vision system can be comprised of a high resolution camera and a computer. Firstly an input device, such as a camera, receives input (frames) from the user. Secondly the interpreting device (computer) is processing those frames. Next step involves analysis of the input to find distinguishing information, a process called feature extraction. Using the features extracted in the previous step, the final model predicts and classifies the object.
The development of real time computer vision applications has been one of the greatest challenges the scientific field has been facing over the years. Computer vision applications that need to process real-time data can suffer from a combination of factors. An example in the case of pose estimation can be the complex definition of the human body and the speed at which the body moves. Moreover the lighting of the scene and the complexity of the background can also have influence on the analysis. It is therefore necessary to bring together a number of scientific study areas, such as artificial intelligence, image processing, pattern recognition and machine learning, in order to succeed.
Design
Thanks to recent advances in image analysis, the field of motion tracking is getting more and more accessible each day. Currently, we can achieve full body tracking using no more than a single RGB camera and a medium-performance PC. Before this technology became reachable, tracking was achieved using more complicated technical stack. For example an array of cameras and markers or by mounting a series of active trackers on the object.
In this project we have decided to aim for solutions that are most widely accessible. Above all we have focused on the cost of the tools. We also focused on solutions that did not require any passive or active wearable trackers or markers.
Full body tracking solutions
During completion of our project we have considered a number of different tools used to achieve full body tracking.
- Computer vision – in this group we have gathered solutions based solely on computer vision: OpenPose, Tensorflow’s PoseNet, MoveNet and MediaPipe’s BlazePose. We have then narrowed it down to solution offering three dimensional joints maps: OpenPose and BlazePose. We have decided to go with BlazePose because OpenPose did not natively support working with a single camera
- AprilTags – technique using cameras in combination with fiducial markers – AprilTags
- Kinect – motion tracking solution based on depth sensing
- MocapForAll – open source motion capture technique working with pictures from multiple monocular cameras. It works by combining multiple 2D maps created using MoveNet into a singular 3D joint map
- Wearable active trackers – e.g. HTC Vive HMD based setup with two controllers and three more trackers. We have refrained from using this solution because of the cost of the setup
- Motion capture rig – last group covers all industry grade tools used for motion capture. e.g Rokoko Smartsuit or system based on array of OptiTrack cameras. Price range of those solutions was out of the project’s scope
Full body rigging in Unity
We have spent a significant part of this project on creating a solution for full body rigging. Each of the tools return tracking data in the form of 3D coordinates of each of the user’s joints in real time. This data is then being used to control the position of the avatar’s joints in Unity. The position of the avatar’s joints reflects the position of user’s joints. Our project required a rigging solution, a solution for controlling the avatar’s limbs movements.
After a thorough research we came to the conclusion that we could rig the avatar using two different approaches. One of them we could achieved using inverse kinematics based solution built into Unity. This would require to create a dependency chain between each adjacent limb in the avatar prefab in Unity’s project scene. Such approach would be very time-consuming for us. User would be also force to redo it every time he would change the avatar model.
The second option that we came up with was different. In contrast to the first one this one was almost entirely code based. It referenced each of the avatar joints by their names making use of the Avatar Configuration tool build into Unity. This solution allowed for a much quicker configuration. Mostly because an avatar following standard naming convention for joints could be automatically mapped by the tool. This approach also speeds up the workflow when the user wants to switch the avatar model.
Each utilized pose estimation tool used by us returns the joints coordinates data in a different format. The positions of joints also differ between the tools. In order to compensate for those differences we had to make the script containing the rigging solution behave differently depending on which pose estimation tool is selected.
Implementation
In our project we have decided to use Unity and Oculus Quest 2. For computer vision full body pose estimation we have decided on using three different tools:
- BlazePose – neural network based solution using a single webcam
- Kinect – depth map based solution
- MocapForAll – neural network (MoveNet) based solution using multiple webcams
BlazePose
BlazePose is a real time convolutional neural network architecture introduced by Google in 2020. It offers an innovative pose tracking tool and a lightweight body pose estimation neural network. While running, it produces 33 main body key points 3D coordinates with the speed of 30 frames per second.
The tool consists of a real time performance tracker – detector, responsible for tasks like face and hand landmark prediction. First the tracker predicts 33 key point coordinates, the human presence and the region of interest. When it comes to its neural network architecture, the result is the outcome of offset, heatmap and regression approach. Training stage make use of heatmaps and offset data. Right after embedding supervision, in which heatmap data are also involved, comes the utilization of the network by the regression encoder network. In our project we have implemented BlazePose using BlazePose Barracuda Unity package.
Kinect
Microsoft Kinect is a motion sensing input device, originally developed for Xbox video game consoles, introduced in 2010 by Microsoft. Kinect V2 contains a certain number of sensing hardware: a depth sensor, an RGB camera and a four microphone array, offering a full body capture, facial, gesture and voice recognition capabilities.
In Kinect V2 a method that measures the time that the light needs to bounce back from a reflected object is used to create the depth maps. This, combined with the constant variable of light speed, can calculate the final distance from various objects. One of the most significant characteristics Kinect V2 has, is the real time automatic identification of anatomical human landmarks. The skeleton tracking is based on training a randomized decision forest algorithm, implementing 100.000 different movement data samples.
Combining HMD tracking with pose estimation
We have spent a notable part of the project’s time on creating a way for combining the tracking of user’s head and hands coming in from HMD and controllers with the whole body joints maps coming in from each of the pose estimation tools. Each of the tools: BlazePose, Kinect V2 and HMD returns coordinates in a different three dimensional reference system. In order to make the avatar work it was crucial to align orientations and compensate for eventual scaling differences between each of those systems.
We have decided to use HMD coordinate system as the main reference to which then adjust each of the individual systems. We have also implemented a calibration routine to compensate for different heights and arms span of different users using the application. Calibration procedure require the user to stand in T-pose for calculation of the scaling multiplier. Calculation is made based on the difference between the corresponding joints coordinates coming from each of the references systems.
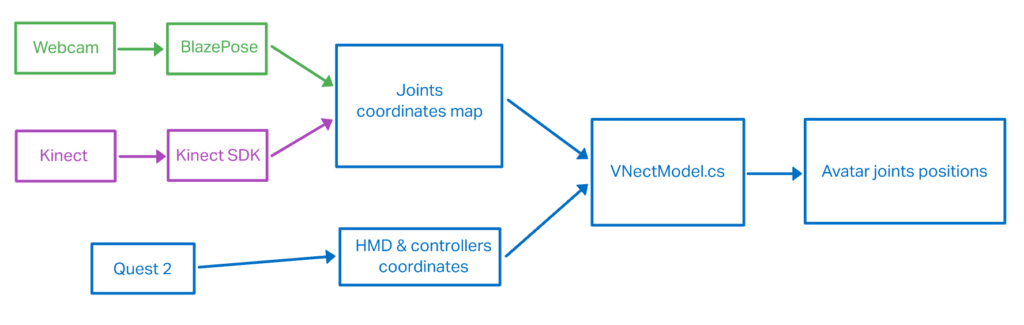
We are using HMD tracking for avatar’s head position, hand controllers, elbows, chest, spine, hips and legs – using results retrieved from pose estimation tools. Additionally we have decided to add an fix in order to compensate for the slightly delay between BlazePose estimation and the HMD tracking. We are calculating the position of the avatar’s elbows using both elbows coordinates from BlazePose algorithm as well as the positions of the controllers.
Result

The final version of the computer vision full body pose estimation Unity project is available on my GitHub. There is also a short instruction describing prerequisites to make it work, difference between scenes, keyboard shortcuts and calibration routine.
Full paper is available in the AAU project library.
Leave a Reply